

Enterprise-Service-Bus für persistente Daten
FLAM hat einen Großteil seines Erfolges der Tatsache zu verdanken, dass wir die logischen Dateninhalte der verschiedenen physischen Dateiformate auf den unterschiedlichen Betriebssystemen, Dateisystemen und Rechnerarchitekturen (vom Großrechner einer Bank bis zum Controller im GSM-Mast der Telekommunikationsunternehmen) so zwischen den verschiedenen Welten überführen können, dass die logischen Inhalte auf dem jeweiligen System korrekt lesbar sind.
Im Laufe der Zeit haben die Heterogenität der Rechnerplattformen und vor allem die Anzahl der physischen Dateiformate (PS / PDS / PDSE (F, FB, FBA, …V, VB, VBA, ..., U, …), VSAM-ESDS / KSDS / RRDS / LDS / …) nachgelassen. Dafür nimmt die Anzahl der logischen Dateiformate (TDA, SWIFT, SEPA, EBICS sind allein 4 Formate für Finanztransaktionen) stetig zu. Wir haben schon immer versucht Welten zu verbinden. In der Vergangenheit waren dies primär stark unterschiedliche Großrechnerarchitekturen. Heute verbinden wir die offene (distributed) Welt (Mac, Windows, Linux, Unix) mit den proprietären Großrechnern von IBM und anderen Herstellern. Für die Zukunft planen wir, alte und neue Anwendungen zu verbinden, welche letztendlich die gleichen logischen Daten verarbeiten, aber diese in unterschiedlichen physischen Repräsentationen (Encodings) erwarten. Ziel ist es zum Beispiel, einem älteren Buchungssystem, welches eine Transaktion im TDA Format erwartet, über unser Subsystem den Satz für diese Cobol-Anwendung im TDA Format bereitzustellen, obwohl das Original in Form einer SEPA-Buchung im XML-Format eingereicht wurde. Umgekehrt soll es auch möglich sein, dass TDA-Bestände einer modernen WebSphere-Applikation im SEPA-konformen XML zur Verfügung gestellt werden können.
Für Online-Transaktionen übernehmen dies heute schon Infrastrukturkomponenten, welche sich unter den Begriff „Enterprise-Service-Bus“ (ESB) einen Namen gemacht haben. Mit FLAM planen wir, eine ähnliche Funktionalität für persistente Datenbestände in der Batchverarbeitung bereitzustellen. Eine Grundvoraussetzung hierfür ist die Unterstützung von bis zu 4 Milliarden verschiedener Elementtypen. Ab der Version 5 kann man in einem FLAM-Archiv nicht nur Datensätze mit Länge und Daten speichern, sondern beliebig viele verschiedene Elementtypen mit Länge, Daten, Attributen und Hashcodes. Diese Erweiterung ermöglicht es, jegliche Art von Datenstruktur in neutraler Form in einem FLAM-Archiv abzulegen. Da die Architektur von FLAM es erlaubt, bei der Ausgabe eines Elements dessen Darstellung frei zu bestimmen, können die gleichen logischen Daten in verschiedenen physischen Repräsentationen bereitgestellt werden.
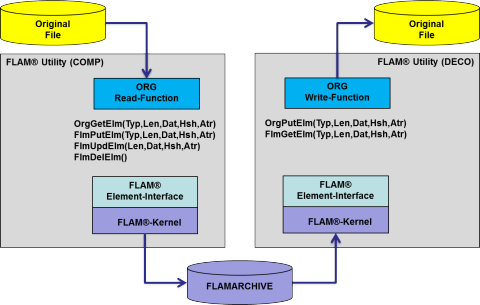
Das Problem hierbei ist, dass man nicht jedes Datenformat auf der Welt in einem Produkt mit der Überführung in die verschiedenen Darstellungsformen unterstützen kann. Daher haben wir dieses Projekt ins Leben berufen, um FLAM für die freie Datenkonvertierung mit einem Interpreter auszustatten, der eine einfache Sprache versteht, mit der man die logischen Datenstrukturen und deren verschiedenen physischen Repräsentationsformen beschreibt. Beim Einlesen mit FLAM muss man mitteilen, in welcher physischen Repräsentation die Daten vorliegen und beim Schreiben kann man dann wiederum das jeweilige Encoding für die Daten wählen.
Eine solche Beschreibungssprache wurde für die ESBs als offener Standard bereits spezifiziert. Unser Ziel ist es, diesen offenen Standard für FLAM zu adaptieren. Hierbei müssen wir aber die Sprache dahingehend erweitern, dass auch Attribute, aber vor allem die Hashwertberechnung für die Suche in FLAM-Archiven beschrieben werden können. Hierdurch wird es dem Anwender möglich, zu definieren, über welche Elemente, wie, ein Hashwert für die spätere Suche mitgeführt werden soll.
Ziel des Projektes ist es, dass FLAM durch die Multi-Format-Konvertierung alten und neuen Anwendungen, welche Dateien lesen und schreiben, über unsere Subsysteme die richtige physische Repräsentation der Daten transparent bereitzustellen bzw. entgegenzunehmen, neutral abzulegen und einer anderen Anwendung in dem von ihr gewünschten Format transparent wieder bereitzustellen.
Eine Vorläufer der freien Datenkonvertiereung ist der Table-Support in FLAM (ab Version 5.1.16), welcher es gestattet mehere Tabellen mit beliebig vielen Spalten in diversen Datenformaten (FB, VB, CSV, TLV, XML, ...) zu verstehen und zwischen diesen Formaten zu überführen. Für komerzielle Anwendungen, wo Transaktionsinhalte, Stücklisten usw. verarbeitet werden, ist dieser Support meist ausreiched.
Diese Lösung ist ein Ergebnis dieses Projektes, wo wir festellen mussten, dass die Interpretation einer Datenformatsbeschreibungssprache bei der Verarbeitung von Massendaten, viel zu viel Aufwand bedeutet. Daher haben wir hier einen neuen Weg eingeschlagen, wo wir die Datenformatsbeschreibung zur Compilezeit lesen und uns den Code für die Überführung der Datenformate in unsere neutralen Elementlisten generieren. Dies verlagert einen großteil der Rechenlast von der Verarbeitungs- zur Compilezeit, was gerade auf Großrechnern extrem viel CPU spart.
Der Table-Support ist hier ein Kompromiss. Die Datenformatsbeschreibung erfolgt hier wie gewohnt über entsprechnede CLP-Strings, welche zur Laufzeit interpretiert werden aber wo, wie bei all unseren Komponenten, die Vorberechnung komplett im Open erfolgt und die Verarbeitung der Daten im Anschluss mit minimaler CPU-Belastung durchgeführt werden kann.
Für das SEPA Instant Payment haben sich unsere Kunden für den Table-Support auch eine synchrone Memory-To-Memroy Konvertierung gewünscht. Des weiteren kamen Anforderungen auf, dass man GZIP und PGP-Files in Memory für MailAttechments erzeugen können soll. Daher stehen jetzt in den Interfaces für JAVA, C/C++, COBOL und PL1 entsprechende Memory-To-Memroy Conversion-Routinen zur Verfügung, was FLAM damit auch zu einer Alterntive für transaktionelle ESB Systeme macht.
Um hier beliebige Datenstrukturen im Speicher aufbauen zu können, haben wir nicht nur fixe und variable lange Format (Längenfeld oder Delimiter) sondern auch Paare aus Länge und Pointer im Programm, womit es unter anderem auch möglich ist, die NULL-Indikation (Unterscheidung von gesetzten Default-Werten von einem Default-Wert in den Daten, welcher daher rührt, dass das optionale Feld (in XML, JSON, ...) gefehlt hat) kenntlich zu machen.