

FLUC-Unterprogramm
Das FLUC-Unterprogramm nutzt die Elementschnittstelle für Originaldaten, um zwischen ihren verschiedenen Darstellungsformen auf den unterschiedlichen Plattformen sowie in den unterschiedlichen Ländern hin und her konvertieren zu können. Hierfür können die Originaldateien nach verschiedenen Verfahren eingelesen, entsprechend konvertiert und wieder weggeschrieben werden, so dass die Daten über verschiedene Plattformen (Records vs. Delimiter) und regionale Unterschiede (Zeichensätze) hinweg verstanden werden. Das FLUC-UP ist ein plattformneutrales Lademodul, welches in Anwendungen, wie zum Beispiel dem FLUC-Utility (FLCL CONV), eingebunden wird. Es ist somit ein Unterprogramm, welches die gesamte Funktionalität der Datenverwaltung des FLUC in einer Funktion zur Verfügung stellt.
Der Nutzen
- Unterstützt alle Funktionen und Schnittstellen des FLUC-Utilitys zur Verarbeitung von Dateien, Datenströmen und anderen Quellen
- Führt alle Schreib- und Lesezugriffe auf Originaldateien unter eigener Kontrolle aus
- Generiert auf Wunsch ein ausführliches Verarbeitungs- und Fehlerprotokoll
- Kann in Anwendungen in beliebigen Programmiersprachen einschließlich JAVA eingebunden werden
- Ist sowohl als statisch zu bindender Objektcode als auch in Form einer dynamischen Bibliothek oder als autarkes Lademodul verfügbar
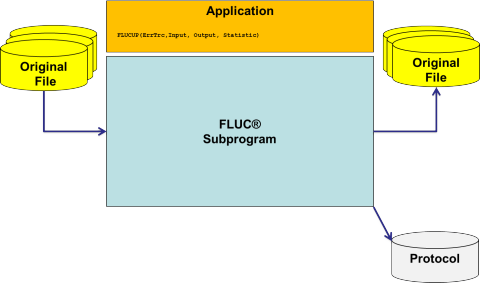
Das Produkt
- Komponentenarchitektur, mit der sowohl für das Lesen als auch für das Schreiben jeweils ein I/O-Verfahren, beliebig viele Konvertierungsverfahren und ein Formatierungsverfahren ausgewählt und mit spezifischen Parametern versehen werden können.
- Es muss einfach der entsprechende String, welcher auch auf der Kommadozeile genutzt wird, als Parameter übergeben werden.
- Es werden ausführliche Statistikwerte, ein Error Trace und verschiedene Logs (z.B bei der Zeichenkonvertierung) erzeugt.
- Es ist somit die Rückmeldung des Verarbeitungserfolgs neben Return Codes auch in Form eines Protokolls möglich.
- Es ist sowohl als 31/32-Bit-Version wie auch als 64-Bit-Version erhältlich.
- Da der gesamte FLUC in nur einer Funktion mit 3 Parameterstrings (Kommadozeile, Dateiname für den Output (optional), Dateiname für das Trace (optional)) abgebildet ist, ist die Integration in eine Anwendung denkbar einfach.
Beispiel
Das folgende Beispiel in COBOL liest eine Datei (DD:INPUT) auf der Host satzweise und gibt diese in CP1252 mit 0x0D0A als Delimiter in Form einer GZIP-Datei für Windows aus. Das Beispielprogram verwendet hierbei zwei DD Namen (INPUT & OUTPUT) und legt die entsprechenden Konvertierungsparameter fest. Hierdurch entsteht ein Batch-Utility mit dem man jede Textdatei (FB/VB/VSAM) auf der Host in eine GZIP-Datei für Windows umwandeln kann (Padding-Zeichen von FB-Dateien werden hierbei unterdrückt (SUPPAD)).
IDENTIFICATION DIVISION.
PROGRAM-ID. SOFCUCNV.
AUTHOR. LIMES DATENTECHNIK GMBH.
*
* SOFCUCNV CALLS THE FLAM-PROGRAM FCUCONV
* TO READ A DATA SET AND CONVERT IT TO A WINDOWS GZIP FILE.
*
* FCUCONV SUPPRESSES TRAILING PADDING CHARACTERS (SUPPAD)
* AND CONVERTS CHARACTER FROM IBM1141 TO CP1252;
* TO EVERY RECORD THE RECORD DELIMITER X'0D0A' IS ADDED,
* ALL DATA WILL BE COMPRESSED BY THE GZIP-LIBRARY.
*
* THIS FILE MAY BE TRANSFERRED BINARY TO ANY WINDOWS SYSTEM,
* ALL DATA ARE WINDOWS-LIKE.
*
* DD-NAMES USED IN THIS EXAMPLE:
*
* INPUT INPUT FILE
* OUTPUT OUTPUT FILE
* LOGOUT LOGFILE
*
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
INPUT-OUTPUT SECTION.
*
DATA DIVISION.
*
WORKING-STORAGE SECTION.
*
01 FCUCONV-PARAMETER.
*
* RETURNCODE
*
02 F-RETCO PIC S9(8) COMP VALUE ZERO.
88 FLAMOK VALUE 0.
*
* LENGTH OF FOLLWING COMMAND
*
02 F-CMDLEN PIC S9(8) COMP VALUE 200.
*
* COMMAND
*
02 F-COMMAND PIC X(200) VALUE
'READ.RECORD(FILE=''DD:INPUT'' CCSID=''1141'' SUPPAD)
- 'WRITE.TEXT(FILE=''DD:OUTPUT''
- ' METHOD=WINDOWS CCSID=''1252'' COMP.GZIP())'.
*
* LENGTH OF PROPERTY STRING (0=NONE)
*
02 F-PROLEN PIC S9(8) COMP VALUE 0.
*
* PROPERTIES
*
02 F-PROPERTY PIC X(200) VALUE ''.
*
* PRINT OUT IN FILE WITH DD-NAME LOGOUT
*
02 F-LOGLEN PIC S9(8) COMP VALUE 9.
02 F-LOGFILE PIC X(9) VALUE 'DD:LOGOUT'.
*
* NO TRACE FILE
*
02 F-TRCLEN PIC S9(8) COMP VALUE ZERO.
02 F-TRCFILE PIC X(44).
/
PROCEDURE DIVISION.
MAIN SECTION.
*
CALL-FLAM-ROUTINE.
*
* CALL FCUCONV
*
CALL 'FCUCONV' USING F-RETCO,
F-CMDLEN,
F-COMMAND,
F-PROLEN,
F-PROPERTY,
F-LOGLEN,
F-LOGFILE,
F-TRCLEN,
F-TRCFILE.
SET-RETURN-CODE.
MOVE F-RETCO TO RETURN-CODE.
MAIN-END.
STOP RUN.
Das folgende COBOL Beispiel liest dank automatischer Formaterkennung normale record-orientierte Dateien (PS(FB/VB), PDS/E(FB/VB), VSAM, ...), binäre Dateien, record- oder text orientierte USS Dateien, binär transferierte Text- und XML-Dateien von anderen Plattformen, binär übertragene GZIP-, BZIP2- oder XZ-Dateien (welche wiederum binäre, Text- oder XML-Daten enthalten können), FLAMFILEs (undefined, stream oder record-Orientiert), und weitere Formate unabhängig vom Zeichensatz und schreibt die ermittelten Sätze in einem Output-Dataset in IBM1141 (sofern die Daten nicht binär sind).
IDENTIFICATION DIVISION.
PROGRAM-ID. SOFLVIEW.
AUTHOR. LIMES DATENTECHNIK GMBH.
*
* SOFLVIEW CALLS THE FLAM-PROGRAM FCUCONV
* TO READ ANY DATA SET AND TO WRITE RECORDS IN A DATA SET
* WITH DD-NAME OUTPUT, LONGER RECORDS WILL BE TRUNCATED
* (RECM=CUT),ALL DATA WILL BE TRANSLITERATED (SYSTAB=ICONV),
* AND, IF NECESSARY, SUBSTITUTED (CHRM=SUB) TO CCSID 1141.
* LOGGING IS IN SHORT FORM WITHOUT TIMESTAMP (FORMAT=DIALOG)
* AND IDENT=FLVIEW.
*
* DD-NAMES USED IN THIS EXAMPLE:
*
* INPUT INPUT FILE
* OUTPUT OUTPUT FILE
* LOGOUT LOG FILE
*
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
INPUT-OUTPUT SECTION.
*
DATA DIVISION.
*
WORKING-STORAGE SECTION.
*
01 FCUCONV-PARAMETER.
*
* RETURNCODE
*
02 F-RETCO PIC S9(8) COMP VALUE ZERO.
88 FLAMOK VALUE 0.
*
* LENGTH OF FOLLWING COMMAND
*
02 F-CMDLEN PIC S9(8) COMP VALUE 240.
*
* COMMAND
*
02 F-COMMAND.
05 FILLER PIC X(120) VALUE
"READ.FILE=DD:INPUT WRITE.RECORD(FILE=DD:OUTPUT,RECM=CUT,"
- "CHRM=SUB,SYST=ICONV,CCSID=1141)".
05 FILLER PIC X(120) VALUE
"LOGGING.STREAM(FORMAT=DIALOG,IDENT=FLVIEW)".
*
* LENGTH OF PROPERTY STRING (0=NONE)
*
02 F-PROLEN PIC S9(8) COMP VALUE 0.
*
* PROPERTIES
*
02 F-PROPERTY PIC X(200) VALUE " ".
*
* PRINT OUT IN FILE WITH DD-NAME LOGOUT
*
02 F-LOGLEN PIC S9(8) COMP VALUE 9.
02 F-LOGFILE PIC X(9) VALUE "DD:LOGOUT".
*
* NO TRACE FILE
*
02 F-TRCLEN PIC S9(8) COMP VALUE ZERO.
02 F-TRCFILE PIC X(44).
/
PROCEDURE DIVISION.
MAIN SECTION.
*
CALL-FLAM-ROUTINE.
*
* CALL FCUCONV
*
CALL "FCUCONV" USING F-RETCO,
F-CMDLEN,
F-COMMAND,
F-PROLEN,
F-PROPERTY,
F-LOGLEN,
F-LOGFILE,
F-TRCLEN,
F-TRCFILE.
SET-RETURN-CODE.
MOVE F-RETCO TO RETURN-CODE.
MAIN-END.
STOP RUN.
Als letztes noch der dazugehörige Sample-Job zum Starten des Beispielprograms, welches Teil unseres Softwarepaketes für die Host ist. Hier wird einfach der INPUT mit DISP=SHR gelesen und der OUTPUT nach SYSOUT=* gestellt, damit man sich den Inhalt der Datei im Job-Log anschauen kann.
//SOFLVIEW JOB 1,'LIMES-DATENTECHNIK', //* TYPRUN=SCAN, // class="B",MSGCLASS=X,MSGLEVEL=(1,1),NOTIFY=&SYSUID //*--------------------------------------------------------- //* //* SAMPLE PROGRAM SOFLVIEW //* "ANYVIEWER" //* READS ANY FILE, CONVERTS DATA //* TO OWN CCSID AND WRITES RECORDS //* TO OUTPUT FILE. //* //*DD-NAMES USED IN THIS EXAMPLE: //* //* INPUT THE FILE TO READ //* OUTPUT OUR OUTPUT DATA SET //*--------------------------------------------------------- //FLVIEW EXEC PGM=SOFLVIEW //STEPLIB DD DSN=&SYSUID..FLAM.LOAD,DISP=SHR //SYSOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //INPUT DD DSN=&SYSUID..FLAM.JOBLIB($ABOUT),DISP=SHR //OUTPUT DD SYSOUT=* //LOGOUT DD SYSOUT=* //*
Dieses Beispielprogramm arbeitet wie unsere CLIST "FLVIEW", welche als Line-Command für ISPF verfügbar ist, um sich den logischen Inhalt eines jeden Dataset im ISPF 3.4 über den Browser anschauen zu können.
Mehr Informationen können Sie der Schnittstellenspezifikation im Downloadbereich entnehmen.