

FLUC - Frankenstein Limes Universal Converter
Der Frankenstein-Limes-Universal-Converter (FLUC) ist das erste Produkt der neuen FL5-Infrastruktur und stellt alle Konvertierungsmöglichkeiten von FLAM5 für Originaldateien direkt zur Verfügung. Er liest Originaldaten von lokalen oder entfernten (SSH) Quellen, wandelt sie über unsere Elementschnittstelle in interne, neutralisierte Elemente um und nach dem Anwenden verschiedener Konvertierungen werden die resultierenden Elemente im gewünschten Ausgabeformat auf einem oder mehreren lokalen oder entfernten Ziele(n) geschrieben.
Der FLUC liest und schreibt FLAMFILEs der Version 4 und älter. Hierdurch ist er gleichzeitig ein Ersatz für das FLAM4-Utility und alle FLAM4-Kunden kommen hierdurch in den Genuss der neuen Konvertierungsmöglichkeiten (ZIP, TAR, HEX (BASE16), BASE32/64/85, OpenPGP (RCF4880 mit zEDC-Support), OpenSSL ENC, GZIP (RFC195x mit zEDC-Support), BZIP2, XZ, ZSTD, LZIP, ICONV, TEXT, TABLE, XML, ...), welche wir mit FLAM5 anbieten. Durch die Integration der Zeichensatzkonvertierung (ASCII/EBCDIC/UNICODE (inklusive String.Latin (XÖV, NPA) Support, NFC/NFD Normalisierung, Eingabehilfe, Reporting uvm.)) aller gängigen Prüfsummen-, Codierungs-, Komprimierungs- und Verschlüsselungsverfahren, verschiedener physischer Dateiformate und dem Verständnis von logischen Dateninhalten (Table-Support (JSON/XML/CSV<->FB/VB)), werden wir die Konvertierungsmöglichkeiten bezüglich der Originaldaten bis hin zur freien Umwandlung von beliebigen logischen Datenformaten weiter ausbauen. Hierdurch wird FLAM ein Bindeglied zwischen allen offen Standards der distributed Welt und den vielen, teils proprietären, Großrechnerformaten.
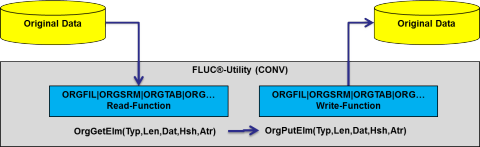
Mit dem FLUC können die Daten auf die verschiedensten Arten und Weisen gelesen, verarbeitet und weggeschrieben werden:
- binär/blockorientiert
- textorientiert (gegen verschiedene Delimiter, mit Steuerzeichensupport)
- satzorientiert (F[B][S][A/M], V[B][S][A/M], U[A/M], VSAM (ESDS/KSDS/RRDS))
- FLAM4FILE (satzorientiert)
- ZIP/Zip64-Archiv oder TARball
- local oder remote (per SSH (SFTP))
- Ausgabe an beliebig viele Ziele gleichzeitig
- und noch vieles mehr
Es können beliebig viele Konvertierungen eingangs- oder ausgangsseitig folgen:
- Encodings: Base16/32/64 (RFC4648)
- mit optionaler Unterstützung von Armor-ASCII/EBCDIC (RFC4880)
- mit optionaler Unterstützung von CRC Checksummen (RFC4880)
- Verschlüsselung: FLAM, OpenPGP (RFC4880), OpenSSL ENC
- Komprimierung: FLAM, GZIP (RFC1950/51/52), BZIP2, LZIP/XZ (LZMA=7ZIP), ZSTD
- Zeichensatzwandlung: ASCII, EBCDIC, UTF-8/16/32, String.Latin, NFD/NFC
- Mitberechnung und Verifikation von Checksummen (MD5/SHA1/SHA256/SHA512/SHA3)
- Generierung und Verifikation von Signaturen (OpenPGP)
- Anti-Virus-Scanning (auch unter z/OS)
- und noch vieles mehr
Die Zerlegung von Daten in Elemente geschieht in Abhängigkeit von der Art der Daten:
- Binär: Datensatz/Datenblock wird auch zu einem Datenelement
- Text: Datenblöcke werden anhand von Textdelimitern in Textsätze zerlegt
- Tabelle: Zerlegung eines Datensatzes (Tabellenzeile) in Elemente pro Spalte
- Überführung zwischen FB/VB (fixen und variablen Strukturen) und CSV/XML/JSON/TLV/TVD Datenformaten
- XML: Datenblöcke werden in einzelne XML-Elemente (Tag, Atribute, Value, ...) zerlegt
- und noch vieles mehr
Mit diesem mächtigen Werkzeug ist es zum Beispiel möglich ein Textdokument, welches unter Windows in UTF-16LE kodiert in ein ZIP-Archiv eingestellt wurde über SSH auf der Host blockorientiert zu lesen, in UTF-8 zu wandeln und in Textsätze zu zerlegen, welche wiederum automatisch beim Schreiben von UTF-8 nach EBCDIC gewandelt werden, wenn man diese lokal satzorientiert in eine VBA-Datei wegschreibt, wobei automatisch ASA-Steuerzeichen hinzugefügt werden. Für Zwecke wie das Anlegen von Backups können die Daten gleichzeitig nach Latin-1 mit 0x0A als Delimiter konvertiert und mit PGP verschlüsselt in einem remoten ZIP-Archiv abgelegen werden. Das Kommando als JCL hierfür würde zum Beispiel wie folgt lauten:
//CONV EXEC PGM=FLCL,PARM='CONV=DD:PARM'
//STEPLIB DD DSN=FLAM.LOAD,DISP=SHR
//SYSPRINT DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//OUTFIL DD DSN=&SYSUID.DOCUMENT,DISP=(NEW,CATLG),
// RECFM=VBA,LRECL=517,SPACE=(CYL,(10,20))
//PARM DD *
read.text(file='ssh://@windows.server/myfiles.zip/?document.txt')
write.record(file='DD:OUTFIL' report='.FLCL.REPORT')
write.text(file='ssh://user@server/my.zip'
method=unix ccsid=latin1
encr.pgp(pass=a'test')
archive.zip())
/*
Für die gelesenen Daten können beliebig viele Ausgabespezifikationen definiert werden. Beim CONV-Kommando entspricht dies, wie oben gezeigt, mehreren WRITE-Angaben. Der gleiche Aufruf mit einer Erweiterung, welche nur über den XCNV zur Verfügung steht, würde wie folgt aussehen:
//XCNV EXEC PGM=FLCL,PARM='XCNV=DD:PARM'
//STEPLIB DD DSN=FLAM.LOAD,DISP=SHR
//SYSPRINT DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//OUTFIL DD DSN=&SYSUID.DOCUMENT,DISP=(NEW,CATLG),
// RECFM=VBA,LRECL=517,SPACE=(CYL,(10,20))
//PARM DD *
input(sav.fil(fio.zip(name='ssh://@windows.server/myfiles.zip/?document.txt')
cnv.zip()
cnv.chr()
fmt.txt()))
output (sav.file(fmt.txt(method=host)
cnv.chr(report='.FLCL.REPORT')
fio.rec(name='DD:OUTFIL')))
output(sav.file(fmt.txt(method=unix)
cnv.chr(to=latin1)
cnv.pgp(pass=a'test')
fio.zip(name='ssh://user@server/mybackup.zip')
fio.blk(name='~/my.pgp')
fio.blk(name='ssh://partner@server/his.pgp')))
/*
Mit dem XCNV-Kommando ist es zusätzlich möglich beliebig viele verschiedene I/O-Verfahren (FIO[BLK() ZIP() FL4() TXT()]) zu definieren. Letzteres ist sinnvoll, wenn man die bereits konvertierten Daten (nur einmal CPU Aufwand) auf verschiedene Ziele verteilen möchte. Zum Beispiel bietet sich dies für PGP-Files an, welche man gleichzeitig lokal wegschreibt, um sie später selbst zu lesen, per SSH zum Partner überträgt und zusätzlich noch in einem ZIP-Archiv für Backup-Zwecke aufbewahrt (siehe oben). Ein anderes Beispiel wäre die Bestückung eines Clusters von Servern mit den gleichen Daten.
Mit dem FLUC wird es auf der Host möglich, alle möglichen Formate der Nicht-Mainframe-Welt richtig in das jeweilge Record-Format zu überführen. Aber auch die Konvertierung zwischen den verschiedenen Dateiformaten auf der Host ist möglich. Da wir mit FLAM5 beliebige Attribute zu einem Element verwalten können, zerlegen wir eine FBA/VBA bzw FBM/VBM Record in die Nettodaten, deren Länge und dem jeweiligen Steuerzeichen. Da nun das Print-Control-Zeichen nicht mehr Bestandteil des Datensatzes ist, kann man zum Beispiel eine FBA- in eine VB-Datei überführen, wobei das Steuerzeichen und trailing Spaces entfernt werden können. Es ist auch möglich Steuerzeichen hinzuzufügen, beizubehalten oder zwischen ASA und Maschinensteuerzeichen umzuwandeln. Bei relativen Dateien (RRDS) nutzen wir die Attribute, um die Lücken in der Datei eindeutig zu kennzeichnen. Hierdurch ist es möglich, eine relative Datei nach verschiedenen Verfahren in sequentielle Datasets zu überführen. Neben RRDS können auch andere VSAM-Datei-Typen über den FLUC aus sequentiellen Dateien geladen oder in diese entladen werden. Des weiteren ist es möglich alle möglichen Dateitypen unter MVS zu lesen und unter USS zu schreiben und umgekehrt. Auch unter UNIX oder Windows sind viele Konvertierungen möglich. Bei dem Beispiel von oben würde das gleiche Kommando unter Windows wie folgt aussehen:
flcl conv read.text(file='myfiles.zip/?document.txt')
write.text()
um den gleichen Text im jeweiligen systemspezifischen Zeichensatz (WINDOWS=LATIN1 und UNIX=UTF-8) mit den richtigen Delimitern (UNIX=0x0A und WINDOWS=0x0D0A) als "document.txt" ausgegeben zu bekommen. Der systemspezifische Zeichensatz wird hierbei anhand der Environmentvariablen LANG bestimmt, welche auf der Host und auch auf den anderen Plattformen, unter anderem auch über die Konfigurationsdaten der FLCL, eingestellt werden kann.
Beim Lesen ist die Originaldatenverarbeitung von FLAM in der Lage den Zeichensatztyp (ASCII/EBCDIC/UTF-8/16/32) automatisch zu erkennen und wählt anhand der Sprachkennung die jeweils passende Codepage aus. Hierdurch wird in nahezu 100% der Fälle die Zeichensatzkonvertierung vollautomatisch richtig gemacht. Nur in dem Fall dass wir EBCDIC erkennen, auf einen deutschen WINDOWs-PC sind und IBM1141 nicht passt, muss man halt die richtige CCSID (Codepage) noch per Hand auswählen.
Dieses kleine Beispiel sollte einmal an einem konkreten Fall verdeutlichen, was der FLUC in der Lage ist zu leisten. Hierbei kann man mit dem FLUC enorm viel CPU- und I/O-Zeit sparen und an Sicherheit gewinnen, da alle Konvertierungen in einem Durchlauf ausgeführt werden können, ohne temporäre Dateien und verschiedene Tools verwenden zu müssen.
Es kann vorkommen, dass man eine Datei remote per SSH in binären Blöcken liest, eine Checksumme prüft, eine BASE64 Kodierung entfernt, eine PGP-Verschlüsselung aufhebt, eine Dekomprimierung nach RFC1951/52 durchführt, nochmal eine Checksumme prüft, dann eine Zeichensatzwandlung mit Transliteration macht und zum Schluss Textsätze auf Basis von Delimitern bildet und sich die Spalten einer CSV- oder XML-Tabelle aus den Daten extrahiert. Beim Schreiben werden die Sätze mit Print-Control- und Padding-Charactern angereichert, ein Prüfwert bestimmt und als FB- oder VB-Datei in ein FLAM4FILE abgelegt, wobei die Tabellen nun fixe oder variable Host-Records darstellen, wo die Strings in EBCDIC als VARCHAR oder gepadded (FIX) und Zahlen in BCD repäsentiert werden. Alles in einem Schritt ohne das gleiche Byte mehr als einmal anzufassen.
Hinzu kommt, dass das Lesen lokal oder remote auf der einen und das Schreiben mehrfach remote oder lokal auf einer anderen Plattform stattfinden kann. Hierbei können die Records oder Blöcke noch in Spalten zerlegt und zwischen verschiedenen Tabellenformaten (FIX, VAR, CSV, TLV, TVD, XML, ...) gewandelt werden.
Mit unseren Pre- und Post-Prozessing können damit global oder pro Datei lokal oder remote vorbereitende Aktionen sowie Folgeprozesse angestoßen werden. Dies ermöglicht zum Beispiel eine Datei per SSH ins USS eines IBM-Großrechners zu übertragen und dann als postprozess in einem MVS-Dataset zu kopieren und wenn dies erfolgreich war die USS-Datei zu löschen. Ein anderes Beipiel wäre die Implementierung eines Quittungsverfahrens bei der Dateiübertragung, wo im Pre-Processing eine Checksumme über das locale Original berechnet und im Postprozessing dies nach der Übertragung auch auf der remoten Seite auch getan wird, sowie über einen weiteren Post-Prozessing-Schritt lokal die beiden Checksummen vergleicht.
*Example 16:* Binary copy of a file per SSH to a remote system, with
checksum calculation over the local original file as pre-process and
over the copied remote file as post process and a final post processing
which compares the check sums. This could be used for example to realize
a receipt for an data transfer.
------------------------------------------------------------------------
flcl xcnv
input(save.file(
fio.blk(file=wrtorg.bin
pre(command='sha1sum [copy]'
stdout=wrtorg.local.sha1))
))
output(save.file(
fio.blk(file=ssh://:limes@tests.limes.de/wrtorg.bin
pst(command='sha1sum [copy]'
stdout=wrtorg.remote.sha1))
pst(command='diff wrtorg.local.sha1 wrtorg.remote.sha1'
stdout=log)))
------------------------------------------------------------------------
*Example 17:* Binary copy of a file per SSH to a IBM mainframe system
with a post processing which copies the file in a MVS data set and
removes the copied file from USS on success.
------------------------------------------------------------------------
flcl xcnv
input(save.file(fio.blk(file=wrtorg.bin)))
output(save.file(
fio.blk(file=ssh://:limes@zos22/wrtorg.bin
pstpro(command='cp -B [copy] "//TEST.XMIT([base])"')
pstpro(command='rm [copy]' on=success))))
------------------------------------------------------------------------
Die beiden Usecases sind eine Kopie aus unserem Handbuch. Das Pre- und Post-Processing dient primäre der Prozessintegration und -automation.